The team that just nailed your last migration is, statistically, the worst group to design your next one.
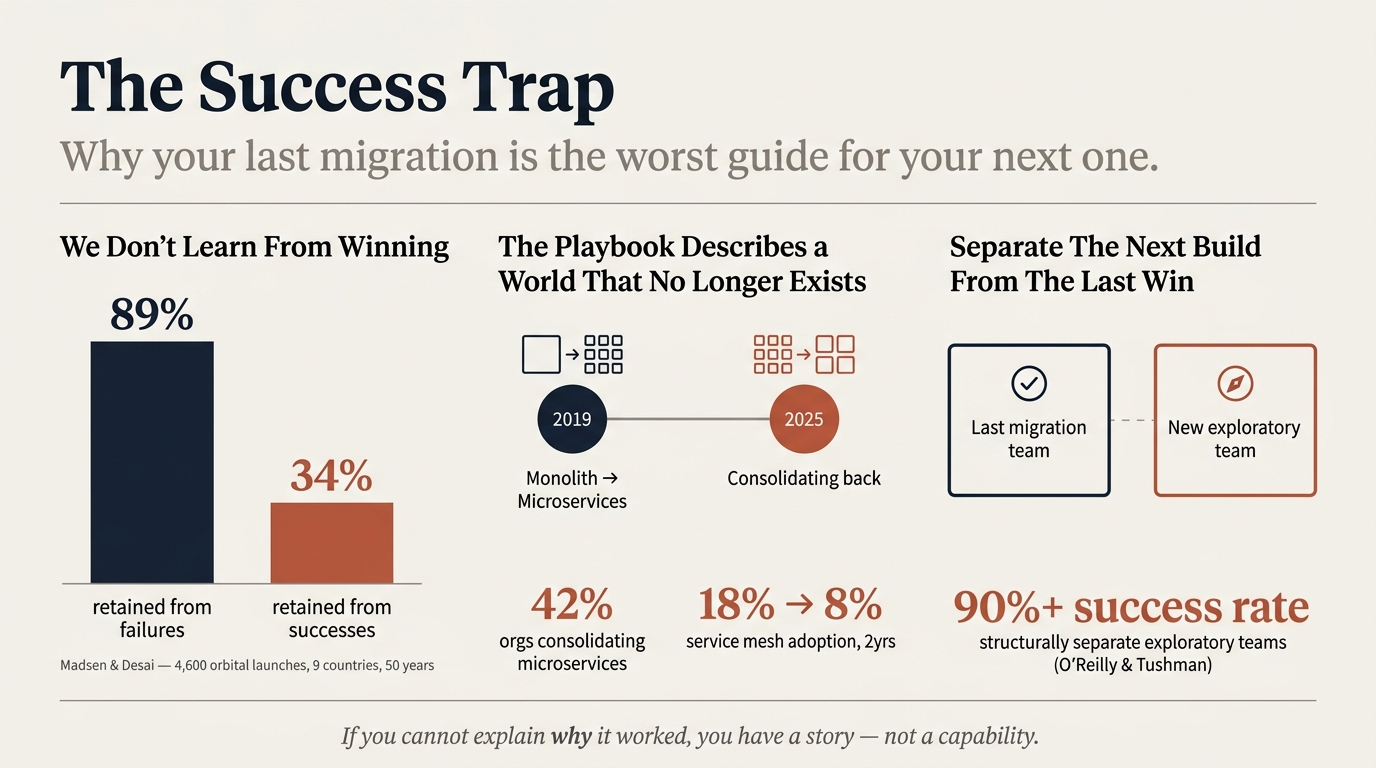
A Madsen and Desai study of 4,600 orbital launches across nine countries over five decades found organizations retained roughly 89% of what they learned from failures a year later, and only 34% from successes. When things go well, we don't study why. We credit whatever we happened to be doing.
Fred Brooks named a version of this fifty years ago. The second system, he warned, is the most dangerous one an architect designs, because confidence replaces caution and every idea sidelined the first time gets jammed into the new one. The vendor that saved us last time becomes the vendor we cannot question, even when the workload, data gravity, and team have all quietly changed underneath us.
I've watched this play out. A monolith-to-microservices split that was right in 2019, applied reflexively in 2024 against a different product and cost structure. CNCF's 2025 survey shows 42% of organizations consolidating microservices back into larger deployment units, with service mesh adoption falling from 18% to 8% in two years. The right answer five years ago is the expensive answer today, and the teams who succeeded loudest are slowest to notice.
The deeper problem is what Gabriel Szulanski called causal ambiguity. The more successful the migration, the harder it is to articulate why it worked. Playbooks capture the visible parts: runbooks, cutover plans, vendor shortlists. The thing that actually drove the win, the engineer who quietly rewrote the data validation layer at midnight, the PM who said no to four stakeholders, the cultural permission to roll back without shame, none of that fits cleanly into a Confluence page. We transfer the surface, lose the substance, and call it a repeatable capability.
Eisenhardt and Martin make a distinction worth holding onto. In stable environments, detailed playbooks earn their keep. In high-velocity environments, simple rules and experiential judgment outperform them, because the playbook describes a world that no longer exists. O'Reilly and Tushman found more than 90% of breakthrough efforts using a structurally separate exploratory team succeeded, while almost none of the alternatives did. Don't ask the team that just shipped the last migration to architect the next one.
A question I've started asking: when we say we have a migration capability, do we actually have one, or do we have institutional muscle memory from the last one, atrophying while we tell ourselves it's a strategy? If we cannot explain why the last one worked, beyond the artifacts it produced, we have a story, not a capability.
The migrations I trust most are the ones where someone asks early whether the last playbook even applies.
When the migration playbook becomes the problem
The strongest empirical finding in this literature is also the one that should anchor any post on this topic: in a study of 4,600+ orbital launches across 9 countries (1957–2004), [1] organizations retained roughly 89% of the knowledge they gained from failures one year later, but only 34% of the knowledge gained from successes [1] (Madsen & Desai, 2010, Academy of Management Journal). The same paper concludes there was "little significant organizational learning from success" at all. That asymmetry — combined with March's 35-year-old "competency trap," Brooks's "second-system effect," and a stack of more recent industry data showing repeat migrations failing harder than first ones — is the analytical spine for the argument that successful migrations actively erode an organization's ability to do the next one. What follows is a dense fact base organized by the eight angles requested, with caveats flagged where source quality is mixed.
The academic foundation: success as the worse teacher
James G. March (1991), "Exploration and Exploitation in Organizational Learning," Organization Science 2(1): 71–87 — over 20,000 Google Scholar citations, [2] one of the most-cited management papers in history. March's formal simulation showed that when an "organizational code" learns faster than its individual members, the code converges on incorrect beliefs because heterogeneity is killed off too quickly. His central claim, usable verbatim: "Adaptive processes, by refining exploitation more rapidly than exploration, are likely to become effective in the short run but self-destructive in the long run." [3] The mechanism: returns to exploitation are more proximate, certain, and visible than returns to exploration, so organizations rationally over-invest in current methods until exploration capacity atrophies.
Levitt & March (1988), "Organizational Learning," Annual Review of Sociology 14: 319–340 — formalized the competency trap: "A competency trap can occur when favorable performance with an inferior procedure leads an organization to accumulate more experience with it, thus keeping experience with a superior procedure inadequate to make it rewarding to use." [4][5] They also coined superstitious learning — the situation where "the subjective experience of learning is compelling, but the connections [between actions and outcomes] are misspecified." After a successful migration, every routine the team followed gets credited for the win, regardless of whether it caused it.
Sitkin (1992), "Learning Through Failure: The Strategy of Small Losses," Research in Organizational Behavior 14: 231–266 — enumerated five "liabilities of success": decreased search and attention, complacency, risk aversion, maladaptive homogeneity, and single-loop learning only. Direct quote: "Where success can foster decreased search and attention, increased complacency, risk aversion, and maladaptive homogeneity, modest levels of failure can promote a willingness to take risks and foster resilience-enhancing experimentation." [6] His five characteristics of "intelligent failure" (planned, uncertain, modest, promptly analyzed, in a familiar domain) provide a useful frame for what a healthy migration retrospective should produce.
Levinthal & March (1993), "The Myopia of Learning," Strategic Management Journal 14: 95–112 — three myopias: temporal (overweighting near outcomes), spatial (overweighting local effects), and failure myopia (under-experiencing failure because of risk aversion). All three reinforce the trap.
Zollo (2009), "Superstitious Learning with Rare Strategic Decisions," Organization Science 20(5): 894–908 — empirical study of U.S. bank mergers. Headline finding: managers' perceived success in prior acquisitions was negatively related to actual performance of the next merger, and the negative effect grew stronger with experience. [7] Mitigating factors: heterogeneity of accumulated experience and deliberate codification of knowledge. [8] Zollo's theoretical hook is Skinner's 1948 pigeon experiments, where pigeons developed elaborate ritualized behaviors associated with food drops on a fixed timer unrelated to behavior. [9]
Haleblian & Finkelstein (1999), Administrative Science Quarterly 44: 29–56 — 449-acquisition sample, found a U-shaped relationship between acquisition experience and performance. [10] "Relatively inexperienced acquirers, after making their first acquisition, inappropriately generalize acquisition experience to subsequent dissimilar acquisitions." [11] First-time successful acquirers most aggressively over-applied the playbook to dissimilar contexts.
Hayward (2002), Strategic Management Journal 23: 21–39 — found that minor acquisition failures improved subsequent acquisition performance, while big successes did not. Failures generated learning; successes generated confidence.
KC, Staats & Gino (2013), "Learning from My Success and from Others' Failure," Management Science 59(11): 2435–2449 — 10 years of data, 71 cardiothoracic surgeons, 6,500+ procedures. [12][13] The asymmetry: surgeons learned more from their own successes than their own failures, but more from others' failures than others' successes. [14][13] Mechanism is attribution: people internalize their own wins (and externalize their own losses) but learn vicariously when watching peers stumble. The team that just ran a successful migration is therefore the worst possible source for the next playbook; outside teams who watched their near-misses are the best. (Caveat: Francesca Gino is at the center of an unrelated data-fabrication controversy; the ManyCoauthors disclosure for this specific paper states Gino did not collect or analyze the data.) [15]
Haunschild & Sullivan (2002), Administrative Science Quarterly 47: 609–643 — U.S. airline incidents 1983–1997. [16] Heterogeneous prior accident causes drove deeper structural inquiry; homogeneous causes produced shallow "blame the pilot" learning. [17] Successful, homogeneous experience suppresses search.
Baum & Dahlin (2007), Organization Science 18(3): 368–385 — U.S. Class 1 freight railroads 1975–2001 (189 railroad-year observations): [18].pdf) "Performance near aspirations fosters local search and exploitive learning, while performance away from aspirations stimulates nonlocal search and exploration." [19] Translation: organizations that just succeeded literally stop exploring.
Denrell (2003), "Vicarious Learning, Undersampling of Failure, and the Myths of Management," Organization Science 14(3): 227–243 — formal mathematical result: risky practices that are unrelated to performance in the full population can appear positively related to performance in a sample of survivors. [20][21] Best-selling management books that codify "what successful firms do" are statistically wrong by construction. The migration playbook is built from a survivor dataset.
Denrell & March (2001), "Adaptation as Information Restriction: The Hot Stove Effect," Organization Science 12(5): 523–538 — once an alternative is rejected based on a possibly mistaken negative early experience, it is no longer sampled, so the negative estimate is never corrected. [22] Asymmetric error correction creates systematic conservatism: [23] the playbook gets falsely confirmed not because it's optimal but because alternatives stop getting tried.
Edmondson (HBR 2011, "Strategies for Learning from Failure") — the most LinkedIn-friendly statistic in the entire literature. When asked how many failures in their organization are truly blameworthy, executives say 2–5%; when asked how many are treated as blameworthy, they say 70–90%. [24] "The unfortunate consequence is that many failures go unreported, and their lessons are lost." [24] The Columbia case is the clearest illustration: NASA managers spent two weeks downplaying the foam strike, anchored on the prior Atlantis mission that had survived an identical anomaly [1] — successful precedent became the very reason engineers' warnings were dismissed. Edmondson's earlier hospital research found, counterintuitively, that better-performing nursing units reported more medication errors, not fewer [25] — because psychologically safe teams surface problems while fear-based teams hide them. [26][27] That foundational finding implies most successful-migration retrospectives are systematically sanitized.
Gino & Pisano (2011), "Why Leaders Don't Learn from Success," HBR 89(4): 68–74 — three impediments to learning from success: fundamental attribution errors (crediting own talent over context and luck), overconfidence bias, and failure-to-ask-why syndrome [28][29] ("Failures get a postmortem. Why not triumphs?"). [28] In a Berkeley experiment with Don Moore, executives randomly cued to recall a success showed higher confidence, more optimistic forecasts, and willingness to make bigger bets [30] — even when the recalled success was due to factors outside their control.
Dahlin, Chuang & Roulet (2018), Academy of Management Annals 12(1): 252–277 — definitive review concluded failure-learning beats success-learning across health care, aviation, manufacturing, and strategy, with three mechanism categories (opportunity, motivation, ability). [31]
Staw (1976), "Knee-Deep in the Big Muddy," Organizational Behavior and Human Performance 16: 27–44 — original escalation-of-commitment finding: personal responsibility is the single strongest predictor of escalating commitment to a chosen course of action. [32] Replicated in at least 8 published experiments (per Brockner 1992 review) [33][34] and by Sleesman et al.'s (2012) meta-analysis in AMJ. Brockner et al. (1986, ASQ) tied escalation explicitly to self-identity: when feedback threatens identity, commitment intensifies. [33] Once leaders own a successful migration, the playbook becomes identity, not technique.
The headline industry numbers are consistent enough to anchor a post but vary in methodological rigor — flag the weaker ones if precision matters.
Digital transformation overall: McKinsey and Kotter both report roughly 70% of transformations fail [35] to meet objectives (Kotter, Leading Change, 1996; reaffirmed across multiple McKinsey RTS publications). [36] BCG's 2020 study of 825 senior executives + 70 BCG client transformations found only 30% succeed, 44% land in the "Worry zone" creating partial value, and 26% in the "Woe zone" delivering less than 50% of target with no sustainable change. BCG's 2021 update raised success to 35%. [37] Bain (2024) reports 88% of business transformations fail to achieve their original ambitions [38] — flag this as cited from secondary sources; primary Bain report should be verified.
Large IT projects (the foundational dataset): Bloch, Blumberg & Laartz (McKinsey + Oxford BT Centre for Major Programme Management), 5,400+ projects over $15M. Average overruns: 45% over budget, 7% over time, 56% less value delivered than predicted. [39] Total cost overrun across the studied projects: $66 billion. [40] 17% of large IT projects are "black swans" with overruns of 200–400%, severe enough to threaten the company's existence. [41][42] Each additional year on a project increases cost overruns by 15%. [41]
Cloud migration: Accenture's 2022 Cloud Migration Handbook reports 45% of cloud migrations fail to achieve expected outcomes. [43] McKinsey's 2023 "In search of cloud value" found only 10% of companies have fully captured cloud's potential value, [44] large companies still run only 15–20% of applications in cloud after years of programs, [45] and breakeven typically requires ~50% adoption [45] — meaning most stalled programs are value-negative. Gartner's 2020 prediction (which played out): 60% of I&O leaders would encounter avoidable public-cloud cost overruns through 2024. [46] Flexera's 2026 State of the Cloud reports wasted cloud spend rose to 29%, reversing a five-year downward trend, driven by AI/PaaS complexity. [47] Gartner's widely circulated "83% of data migration projects fail or exceed budgets and schedules" [48] is best treated as industry shorthand — primary methodology is not publicly available.
ERP: Industry consensus from Panorama Consulting's annual reports holds that roughly 50% of ERP implementations fail on first attempt, that ERP overruns commonly run 3–4× initial budget, [49] that timelines extend ~30% beyond original schedule, and that 51% of companies experience operational disruptions at go-live. [49][50] A Resulting IT survey of 113 individuals across 105 SAP customers found only 36% felt the project kept to its original plan; 48% said it failed to achieve business objectives; 52% reported being over budget. [51]
Monolith-to-microservices reversals — the clearest evidence that yesterday's successful pattern becomes tomorrow's failure:
- Amazon Prime Video (March 2023): Video Quality Analysis team rebuilt their distributed Step Functions/Lambda system as a monolith on EC2/ECS. [52] Over 90% reduction in infrastructure cost [53][54] plus higher scaling capacity; [55] original architecture hit a hard ceiling at 5% of expected load. [56] Direct quote (Marcin Kolny): "Moving our service to a monolith reduced our infrastructure cost by over 90%." [57][58] (Caveat: Adrian Cockcroft has argued this is more a microservices refactoring than a true monolith reversal; the cost number is solid, the framing is contested.) [56]
- Segment (2018, retold at QCon London 2020): Split monolith into 50+ destination microservices [59] in 2014, hit hypergrowth, defect rate exploded, velocity collapsed; migrated back to a monolith called Centrifuge. [60]
- Istio reverted its control plane to monolith due to operational complexity; InVision did the same. [55]
- CNCF 2025 survey: 42% of organizations are actively consolidating microservices back to larger deployment units; service mesh adoption fell from 18% in Q3 2023 to 8% in Q3 2025. [61]
- Academic synthesis: Su et al. (2024), "From Microservice to Monolith," Electronics 13(8): 1452 — identified 5 dominant reasons for reversal: cost, complexity, scalability, performance, organization. [62]
Re-platforming specifically: Practitioner data is sparser. Ethan Knox's review of 13 replatformings he personally witnessed across 15 years found only 4 yielded positive outcomes — a 70% failure rate [63] in his cohort. Rich Mironov's industry pattern: v1.0 typically covers 60% of legacy use cases, v1.1 ~70%, v1.35 ~78%, v2 ~82%, never reaches full parity, [64] and companies frequently end up running both systems indefinitely ("4,800 customers on the new platform, 200 on legacy, both supported for the next decade"). [65] Ron Lichty's rule of thumb: "Start with the worst possible estimate for how long replatforming might take and then triple it." [64]
Standish CHAOS Report 2020 (50,000+ projects): 31% successful, 50% challenged, 19% failed. Small projects ~90% success rate; large projects under 10%. Projects exceeding $10M are more than 10× as likely to be cancelled as projects under $1M. [66] Methodology has been criticized in ACM Queue (Varajão et al., 2024); cite with context.
Named, quantified failures useful as anchors:
- Lidl/SAP eLWIS (2011–2018): €500M write-off after seven years; [67][68] reverted to legacy "Wawi." [68]
- Revlon/SAP S/4HANA (Feb 2018): ~$64M in unfilled orders, [69] $54M direct remediation, [70][71] 6.4% stock drop, [72][69] multiple class actions; Brightwork Research estimates total remediation reached $585M. [71]
- Birmingham City Council/Oracle Fusion: Original budget £19M; latest projection £216.5M by April 2026 (Audit Reform Lab, University of Sheffield) [73] — 11×+ overrun, contributed to the council's effective bankruptcy in 2023, [73] council is now re-implementing Oracle "out of the box" after the first attempt failed. [74]
- VA/Oracle-Cerner EHR Modernization: Original 2018 contract $10B; current lifecycle estimate $37.2B, [75] with IDA projections reaching ~$50B. [76] VA paused all rollouts April 2023 after deploying to only 5–6 of 170 medical centers. [76] VA Inspector General (Sept 2024) cited 800+ major performance incidents [77] since launch and 149 patients harmed [75] in the Spokane "unknown queue" incident. GAO (March 2025): only 13% of VA staff using the new EHR believed it made VA as efficient as possible; 58% believed it increased patient safety risks. [77]
- NHS National Programme for IT (NPfIT): Launched 2002, cancelled 2011; [78] original budget £2.3B → £12.7B final, [79] with realized benefits of only ~£3.7B [78] — the UK Public Accounts Committee called it "one of the worst and most expensive contracting fiascos" Wikipedia ever.
- U.S. Air Force ECSS: $1.03B cancelled (2012) with no significant capability delivered. [80][81]
- Hertz v. Accenture (2019): $32M+ lawsuit over failed website/mobile redesign. [82]
- Haribo/SAP S/4HANA (2018): Caused supermarket gummy-bear shortages and a 25% Gold Bear sales decline in Germany. [67]
- Hershey/SAP R/3 (1999): Compressed 48-month plan to 30 months, [83] missed $100M of Halloween orders, stock fell 8%.
Repeat migrations performing worse — the directly on-thesis cases:
- Birmingham is now executing its second failing Oracle implementation after the first failed [74] and is dealing with a third-party-sustained legacy SAP from 1997 underneath.
- Invacare had ERP problems 2005–2009; its second SAP upgrade in 2021 also failed and was halted indefinitely. [84]
- U.S. Air Force ECSS: the Accenture-led successor to the cancelled $1.03B program [85] is itself behind expectations.
Healthcare and regulated-industry specifics
KLAS Arch Collaborative 2025 EHR Implementations Report (the most current healthtech-specific dataset):
- Only 38% of healthcare leaders said their recent EHR implementation hit the mark. [86]
- 40% reported significant misses; 22% reported average satisfaction with room for improvement. [87]
- 73% of organizations had a below-average Net EHR Experience Score post-implementation. [87]
- 57% of clinicians reported their organization and IT did not support implementation well. [87]
- Customer satisfaction with EHR implementations has dropped more than any other healthcare-IT metric since 2022. [87]
- Top barriers (n=180 orgs): change management/adoption (34%), [86] training (30%), [86] provider staffing (22%). [86]
Other healthtech-specific data:
- Industry consensus: 30–50% of EHR implementation projects fail. [79]
- Black Book: 17% of medical practices say they're likely to switch out their first-choice EHR. [79]
- Mayo Clinic Proceedings: EHRs scored an "F" on the System Usability Scale (vs. Google "A," Microsoft Word "C"). [88]
- Stanford: 74% of clinicians reported increased work hours post-EHR; 71% attribute burnout to EHRs. [88]
- Quantros 2007–2018: 18,000 EHR-related patient safety events logged; 3% caused harm; 7 deaths. [88]
- Leapfrog 2016: hospital EHR medication-ordering functionality failed to flag potentially harmful drug orders in 39% of test simulations; 13% could have been fatal. [88]
- Healthcare cloud: KMS Healthcare reports 62% of healthcare cloud migrations fail or face more difficulties than anticipated; [89] average healthcare data breach cost $10.93M per incident in 2023 (IBM/Ponemon — highest of any industry).
Brooks's second-system effect and Conway's Law
Fred Brooks, The Mythical Man-Month (1975, Anniversary Edition 1995), Chapter 5, p. 55 — the canonical quote for any post on this topic: "An architect's first work is apt to be spare and clean. He knows he doesn't know what he's doing, so he does it carefully and with great restraint... Sooner or later the first system is finished, and the architect, with firm confidence and a demonstrated mastery of that class of systems, is ready to build a second system. This second is the most dangerous system a man ever designs. ... The general tendency is to over-design the second system, using all the ideas and frills that were cautiously sidetracked on the first one." [90] Brooks's named example was OS/360, which poured architectural effort into static-overlay support precisely as dynamic memory allocation made it obsolete — "refining techniques whose very existence has been made obsolete by changes in basic system assumptions." [91]
Modern validations of the second-system pattern:
- Netscape 6 / Mozilla rewrite (2000): Joel Spolsky called the rewrite "the single worst strategic mistake that any software company can make." [92] Cost Netscape three years of zero-feature releases between Navigator 4.0 and Netscape 6. [92] Lou Montulli, original Navigator engineer: "It had taken 3 years of tuning to get code that could read the 60 different types of FTP servers. Those 5,000 lines of code may have looked ugly, but at least they worked." [92]
- Perl 6 / Raku: announced 2000, shipped 2015, diverged so far it was renamed.
- Python 3: Released 2008, end-of-life for Python 2 extended five years to 2020 because of slow adoption [93] — a 12-year tail for a language transition.
Conway's Law (Melvin Conway, 1968, "How Do Committees Invent?" Datamation 14(4): 28–31). The original quote: "Any organization that designs a system... will inevitably produce a design whose structure is a copy of the organization's communication structure." [94][95] Backstory worth knowing: Conway submitted the paper to HBR in 1967 and was rejected on the grounds that he "had not proved [his] thesis." [96][97] A second Conway quote useful for the post: "The very act of organizing a design team means that certain design decisions have already been made."
Empirical validations of Conway's Law:
- MacCormack, Baldwin & Rusnak (2012), "Exploring the Duality between Product and Organizational Architectures," Research Policy 41(8): 1309–1324 — matched-pair natural experiment using Design Structure Matrices: products developed by loosely-coupled (open-source) organizations were "significantly more modular" than products from tightly-coupled (commercial) organizations [95] developing functionally identical software. [96] The magnitude of difference was a factor of six in propagation potential. (Working-paper version: factor of eight; use the published "six.")
- Nagappan, Murphy & Basili (2008), Microsoft Research/University of Maryland, ICSE 2008 — studied Windows Vista (3,400+ binaries, 50M+ lines of code). Organizational metrics outperformed code-based metrics (churn, complexity, coverage, dependencies, pre-release bugs) at predicting failure-prone binaries, with precision ~73% and recall ~75%. Empirical sledgehammer behind "your org chart ships."
Inverse Conway Maneuver (term coined by LeRoy & Simons, Cutter IT Journal, December 2010). Forsgren, Humble & Kim, Accelerate (2018) — 4 years of data, 23,000+ survey responses, 2,000+ organizations across all sizes and industries. Their direct conclusion: "High performance is possible with all kinds of systems, provided that systems — and the teams that build and maintain them — are loosely coupled." Loosely coupled architecture was "the biggest contributor to continuous delivery — larger even than test and deployment automation."
Skelton & Pais, Team Topologies (2019) — directly on the user's thesis: "The way teams are set up and interact is often based on past projects and/or legacy technologies (reflecting the latest org-chart design, which might be years old, if not decades)." The structure that succeeded last time becomes the constraint on the next migration before any architectural decisions are made.
Structural inertia and the paradox of success
Hannan & Freeman (1984), "Structural Inertia and Organizational Change," American Sociological Review 49(2): 149–164. Key empirical claim: older organizations have more inertia than younger ones, and high inertia is the outcome of selection — organizations that survive are those that reliably reproduce their structure with high fidelity. The very reliability that made your last migration work is the same force that ossifies the structure for the next one. "Sunk costs in plant, equipment, and personnel, the dynamics of political coalitions, and the tendency for precedents to become normative standards" are their three internal sources of inertia.
O'Reilly & Tushman (2004), "The Ambidextrous Organization," HBR 82(4): 74–81 — study of 35 breakthrough innovation attempts. More than 90% of attempts using an ambidextrous structure (separate exploratory units with different processes, structures, and culture from the exploitative units, held together at senior leadership) succeeded; none of the other organizational designs achieved a comparable success rate. The lesson: don't ask the team that just succeeded to design the next thing.
Henderson & Clark (1990), "Architectural Innovation," Administrative Science Quarterly 35(1): 9–30 — the canonical paper on why incumbents whose internal communication channels are tuned to one architecture systematically fail when "architectural innovation" reshuffles how components connect, even when the components themselves are unchanged. Direct map to monolith → microservices → serverless transitions: same components, different connection topology, organizational mismatch.
Pfeffer & Sutton, "casual benchmarking," and the fragility of best-practice transfer
Pfeffer & Sutton (2006), Hard Facts, Dangerous Half-Truths, and Total Nonsense (HBS Press) and HBR (January 2006). Their two-part diagnosis of why playbook reuse fails: "People copy the most visible, obvious, and frequently least important practices," and "companies often have different strategies, different competitive environments, and different business models — all of which make what they need to do to be successful different from what others are doing." Pfeffer's own framing names exactly the user's target: "act on the basis of facts rather than casual benchmarking, belief or ideology, and what they thought made sense or what they had done in the past."
Their canonical case: United Airlines's "Shuttle by United" (1994), copying Southwest's casual uniforms, 737s, no-food, fast turnarounds. Result: Southwest ended up with higher market share in California than before United launched its imitation; Shuttle was shuttered. Wharton's John Paul MacDuffie made the same diagnosis of U.S. automakers copying Toyota's visible mechanisms (JIT, SPC charts, andon cords) without absorbing the underlying logic.
Cognitive biases driving migration playbook overuse
Tversky & Kahneman (1973, 1974) established the availability heuristic — probability judgments scale with how easily instances come to mind, with vivid and emotional events systematically over-weighted. Bazerman & Moore's Judgment in Managerial Decision Making applies this directly: a recent successful migration becomes the most "available" reference class regardless of its relevance to the current decision.
Survivorship bias — the Wald story: Abraham Wald, working at Columbia's Statistical Research Group during WWII, was asked where to add armor on bombers based on bullet-hole distributions on returning planes. His insight: the returning planes were a biased sample; the missing data was the planes that didn't return. His estimate: a bomber survived a single hit to the engine ~60% of the time, but a hit to the fuselage ~95% of the time. Recommendation: armor the areas with no bullet holes on returners — engines and cockpit. Migration playbooks are built from the bombers that came back; the fatal hits on prior migrations are invisible because those projects were killed, scoped down, or quietly rebranded. Denrell (2003) put the math behind this: in a sample of survivors, risky and low-quality practices unrelated to performance in the full population can appear positively correlated with performance.
Rosenzweig (2007), The Halo Effect identified four delusions especially relevant to playbook construction: the halo effect (successful project → all attributes praised retrospectively), connecting the winning dots (no comparison to failures), rigorous research (volume ≠ validity — direct critique of Built to Last, Good to Great, In Search of Excellence), and lasting success (truly sustained outperformance essentially never happens; the "Visionary companies" of Built to Last regressed sharply).
Dittmar & Duchin (2016), Review of Financial Studies — empirical hot-stove evidence: 9,000 CEOs and CFOs, those with adverse financial-shock experience held less debt and invested less for years afterward. Real-world asymmetric error correction at the executive level.
When playbook reuse genuinely works
The literature is not uniformly anti-playbook. The evidence on when repeatable approaches succeed is the most important nuance for the post.
Zook & Allen (Bain, 2012), Repeatability — multi-year study of 200+ companies. Findings: only ~9% of global companies achieve more than modest sustained profitable growth over a decade; new growth initiatives succeed only 20–25% of the time; ~75% of long-lasting "Sustained Value Creators" had a Great Repeatable Model at their core; strong adherence to all three design principles increases odds of sustaining success by 4–6×. The three principles: (1) a well-differentiated core with explicit replication systems, (2) clear non-negotiables embedded in frontline action, (3) closed-loop learning systems. Crucially: repeatability works when the meta-design is being repeated, not when specific tactical playbooks are.
Eisenhardt & Martin (2000), "Dynamic Capabilities: What Are They?" Strategic Management Journal 21(10–11): 1105–1121 — the most important nuance in the entire literature for migration work. Dynamic capabilities have "significant commonalities across firms (popularly termed 'best practice')", but their form depends on environment volatility: in moderately dynamic markets, dynamic capabilities resemble detailed, analytic, stable routines with predictable outcomes — playbooks work; in high-velocity markets, they are simple, highly experiential, fragile processes with unpredictable outcomes — playbooks fail and "simple rules" are the right approach. Multiple paths to the same outcome; rigid replication is wrong by design.
Winter (2003), "Understanding Dynamic Capabilities," Strategic Management Journal 24(10): 991–995 — established the hierarchy of capabilities (zero-order operational capabilities; first-order routines that change operational capabilities; second-order routines that change first-order routines) and made the underrated argument that firms can also accomplish change via "ad hoc problem solving", and whether higher-order capabilities are worth the investment depends on cost-benefit. Sometimes building a playbook is more expensive than just solving each migration as a unique problem.
Cohen & Levinthal (1990), "Absorptive Capacity," ASQ 35(1): 128–152 — tested with 1,719 business units in U.S. manufacturing. Key mechanism: prior related knowledge is what makes new knowledge absorbable. Genuine meta-capability is having absorbed enough about why prior migrations worked to recognize when a new context is fundamentally different; running the same playbook is muscle memory — pattern-matching without comprehension.
Szulanski (1996), "Exploring Internal Stickiness," Strategic Management Journal 17(Winter Special Issue): 27–43 — 271 observations of 122 best-practice transfers in 8 companies. The bombshell finding: contrary to the conventional "they didn't want to" explanation, the dominant barriers to internal knowledge transfer are knowledge-related, not motivational. Causal ambiguity — uncertainty about why a practice works, even ex post — was the most stable predictor of transfer failure across all four stages of the transfer process (initiation, implementation, ramp-up, integration). Implication directly on the user's thesis: the more successful the migration, the more tacit and inarticulable its success factors are; the playbook captures the codifiable surface, while the actual driver goes home with the people.
Argote and the pizza study (Darr, Argote & Epple, 1995), Management Science 41(11): 1750–1762 — 36 pizza stores in southwestern Pennsylvania across 10 franchisees. Knowledge transferred across stores owned by the same franchisee, but not across stores owned by different franchisees — same processes, recipes, equipment, brand. Same playbook + same processes + different leaders = no transfer.
The NUMMI case (Adler & Cole, 1993; Shih, 2024 HBS case) — Toyota and GM joint venture, 85% of GM-Fremont's previously militant workforce rehired, became the most productive auto plant in the U.S. with quality matching Japan. GM never successfully transferred the lessons to other GM plants despite decades of attempts. The physical playbook (kanban, andon, takt time) transferred easily; the cultural software (psychological safety to pull the cord, surfacing problems) did not. Direct illustration of the meta-capability vs. specific-capability split.
Danaher Business System — the strongest counterexample. Earnings per share grew ~10,000% from 1990 to 2023; stock returned 35,000%+ since the 1980s. 50+ acquisitions between 2001–2006; ~60 principal subsidiaries today. Why it works: the operating system is genuinely codified (People, Plan, Process, Performance applied via Kaizen-derived tools, value stream mapping, policy deployment) and the selection criteria for what to acquire are explicit. Critique from a former director: "If it's too rigid, maybe you lose creativity… they have such a high turnover rate in management." Even the best-functioning playbook has costs.
Berkshire Hathaway is the architectural counterpoint to Danaher: a meta-playbook of permanent capital, insurance float, decentralized trust-based oversight, and minimalist due diligence — not an operational playbook. The two together illustrate that "repeatable" can mean very different architectural choices.
The "fighting the last war" framing
The phrase traces to Lt. Col. J. L. Schley, The Military Engineer (1929): "There is a tendency in many armies to spend the peace time studying how to fight the last war." Cohen & Gooch (1990), Military Misfortunes: The Anatomy of Failure in War offers the cleanest formal framework for business application: failure occurs through failure to learn (from past experience), failure to anticipate (the next war's conditions), and failure to adapt (in real time) — and catastrophe comes from the combination. Joseph Bower's HBR review (July–August 1990) translated the framework explicitly to corporate strategy. Stephen Rosen's Winning the Next War (Cornell, 1991) offers the counterintuitive corollary: innovation is easier in peacetime than in war because the fog of war forces reliance on existing playbooks. Direct migration analogue: under cost or compliance pressure, teams fall back on the last playbook precisely when they should be questioning it.
Path dependence and vendor lock-in
W. Brian Arthur (1989), "Competing Technologies, Increasing Returns, and Lock-In by Historical Events," Economic Journal 99(394): 116–131. Four sources of increasing returns directly applicable to vendor lock-in: large fixed-to-marginal cost ratios (sunk infrastructure), learning effects (users get better at it), coordination/network effects, and adaptive expectations. Once locked in, the cost to change rises with accumulated specialization. Maps cleanly to Epic/Cerner, AWS/Azure, and HL7/FHIR ecosystem effects in healthtech: past success with a vendor on Migration A creates increasing returns that drive an irrational vendor choice for Migration B. (Caveat: don't lean on Arthur's QWERTY example as proof of inefficient lock-in — Liebowitz & Margolis, 1990 and 1995, JLEO, empirically challenged it. Use Arthur's mechanisms, not his examples.)
The most LinkedIn-anchorable findings, ranked
The findings most likely to make a reader stop scrolling and question their own playbook:
- Madsen & Desai (2010): 89% retention from failures vs. 34% from successes — the cleanest single number.
- KC, Staats & Gino (2013): the team that ran the migration is the worst source for the playbook; outsiders observing their near-misses learn more than they do — directly counterintuitive.
- Edmondson: executives say 2–5% of failures are truly blameworthy, but 70–90% are treated that way — explains why retrospectives are sanitized.
- MacCormack et al. (2012): tightly-coupled organizations build products six times more coupled than loosely-coupled ones building the same thing — the empirical hammer behind Conway's Law.
- Brooks's verbatim quote: "This second is the most dangerous system a man ever designs" — 50 years old and still the perfect headline.
- Szulanski: causal ambiguity, not motivation, is the dominant barrier to transferring best practices — the more successful the migration, the less transferable it is, because nobody can fully articulate why it worked.
- O'Reilly & Tushman: ambidextrous structures succeeded in 90%+ of cases; no other structure came close — the team that just succeeded should not be the team designing the next migration.
- CNCF 2025: 42% of organizations are actively consolidating microservices back to monoliths; service mesh adoption fell from 18% to 8% in two years — the live, current evidence that yesterday's right answer is today's wrong one.
- Birmingham City Council: £19M Oracle budget became £216.5M, contributing to municipal bankruptcy, on its second attempt — concrete second-system disaster.
- VA Oracle-Cerner: $10B → $37.2B; only 13% of VA staff believe it makes them as efficient as possible; 58% believe it increases patient safety risks — healthtech-specific catastrophe.
Source-quality caveats worth flagging before publishing
A few stats commonly appear in industry decks but should be treated carefully if a post is going to be scrutinized: Gartner's "83% of data migrations fail" lacks a publicly-disclosed methodology; the Bain "88% of business transformations fail" comes through secondary citations and the primary report should be verified; the "70% of transformations fail" figure has multiple lineages (Kotter 1996, McKinsey practitioner experience, BCG validation) and is best attributed as a cross-firm consensus rather than a single study; Standish CHAOS methodology has been formally criticized in ACM Queue; the Madsen & Desai "89% / 34%" specific figures come from depreciation-parameter modeling reported in strategy+business's summary of the AMJ paper rather than a single headline number in the published abstract — the paper's underlying conclusion ("little significant organizational learning from success") is unambiguous; KC, Staats & Gino's findings stand because Gino did not collect or analyze that data per the ManyCoauthors disclosure, separate from her unrelated retraction controversy. The Wald survivorship-bias story is real (CRC 432, reprinted 1980) but some popular versions add fictional dialogue; the substantive math is genuine. Adrian Cockcroft and others contest framing the Amazon Prime Video case as a "monolith win" — the 90% cost number is solid, the framing is contested.
- strategy+business — https://www.strategy-business.com/article/10314e
- Academia.edu — https://www.academia.edu/47553626/Revisiting_James_March_1991_Whither_exploration_and_exploitation
- IDEAS/RePEc — https://ideas.repec.org/a/inm/ororsc/v2y1991i1p71-87.html
- Pbworks — https://sjbae.pbworks.com/f/levitt_march_1988.pdf
- Archive — https://ia802305.us.archive.org/23/items/15341_Readings/15341_Readings/Organizational_Learning_and_Change/Levitt_March_Org_Learning_text.pdf
- Taylor & Francis Online — https://www.tandfonline.com/doi/full/10.1080/09540962.2021.1965307
- INFORMS — https://pubsonline.informs.org/doi/abs/10.1287/orsc.1090.0459
- ResearchGate — https://www.researchgate.net/publication/200465308_Deliberate_Learning_and_the_Evolution_of_Dynamic_Capabilities
- ResearchGate — https://www.researchgate.net/publication/220520939_Superstitious_Learning_with_Rare_Strategic_Decisions_Theory_and_Evidence_from_Corporate_Acquisitions
- Google Scholar — https://scholar.google.com/scholar_lookup?hl=en&volume=44&publication_year=1999&pages=29-56&journal=Administrative+Science+Quarterly&issue=1&author=J.+Haleblian&author=S.+Finkelstein&title=The+influence+of+organizational+acquisition+experience+on+acquisition+performance:+A+behavioral+learning+perspective
- Semantic Scholar — https://www.semanticscholar.org/paper/The-Influence-of-Organizational-Acquisition-on-A-Haleblian-Finkelstein/8854ed8ebb76843568bfe36548d636e108245f60
- INFORMS — https://pubsonline.informs.org/doi/10.1287/mnsc.2013.1720
- DSpace — https://repository.upenn.edu/fnce_papers/116/
- IDEAS/RePEc — https://ideas.repec.org/a/inm/ormnsc/v59y2013i11p2435-2449.html
- Manycoauthors — https://manycoauthors.org/gino/86
- Google Scholar — https://scholar.google.com/scholar_lookup?title=Learning+from+complexity:+Effects+of+prior+accidents+and+incidents+on+airlines+learning&=&author=P.+R.+Haunschild&=&author=B.+N.+Sullivan&=&publication_year=2002&=&journal=Administrative+Science+Quarterly&=&pages=609-643&=&doi=10.2307/3094911
- SSRN — https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1004422
- Ntnu — http://www.iot.ntnu.no/innovation/norsi-pims-courses/Greve/Baum%20&%20Dahlin%20(2007
- Hal — https://hec.hal.science/hal-00480399
- Stanford Graduate School of Business — https://www.gsb.stanford.edu/faculty-research/publications/vicarious-learning-undersampling-failure-myths-management
- Oxford University Research Archive — https://ora.ox.ac.uk/objects/uuid:a8102a34-f7a4-40de-91c0-139355f97358
- ResearchGate — https://www.researchgate.net/publication/245188791_Adaptation_as_Information_Restriction_The_Hot_Stove_Effect
- Cambridge Core — https://www.cambridge.org/core/books/abs/sampling-in-judgment-and-decision-making/hot-stove-effect/9B93B91C9C0C7A4A7240A6C21F759BBA
- Chieflearningofficer — https://www.chieflearningofficer.com/2012/05/03/avoid-playing-the-blame-game/
- Alameda Health System — https://www.alamedahealthsystem.org/wp-content/uploads/2020/08/2020-08-27-QPSC-C-Chair-Articles-COMBINED.pdf
- AAMC — https://www.aamc.org/news/amy-edmondson-psychological-safety-critically-important-medicine
- Lean Blog — https://www.leanblog.org/2020/01/amy-edmondson-psychological-safety-speaking-up/
- Harvard Business Review — https://hbr.org/2011/04/why-leaders-dont-learn-from-success
- ResearchGate — https://www.researchgate.net/publication/51067859_Why_leaders_don't_learn_from_success
- Scribd — https://www.scribd.com/document/776560702/Why-Leaders-don-t-Learn-from-success
- Academy of Management Journal — https://journals.aom.org/doi/10.5465/annals.2016.0049
- SciSpace — https://scispace.com/papers/knee-deep-in-the-big-muddy-a-study-of-escalating-commitment-1nh3a4zs29
- Columbia Business School — https://business.columbia.edu/sites/default/files-efs/pubfiles/11642/vicarious_entrapment.pdf
- ResearchGate — https://www.researchgate.net/publication/247716666_Escalation_The_Determinants_of_Commitment_to_a_Chosen_Course_of_Action
- McKinsey & Company — https://www.mckinsey.com/~/media/mckinsey/business%20functions/people%20and%20organizational%20performance/our%20insights/successful%20transformations/december%202021%20losing%20from%20day%20one/losing-from-day-one-why-even-successful-transformations-fall-short-vf.pdf
- McKinsey & Company — https://www.mckinsey.com/capabilities/transformation/our-insights/common-pitfalls-in-transformations-a-conversation-with-jon-garcia
- BCG — https://www.bcg.com/publications/2021/performance-and-innovation-are-the-rewards-of-digital-transformation-programs
- Mavim — https://blog.mavim.com/why-70-of-digital-transformations-fail-insights-and-solutions
- McKinsey & Company — https://www.mckinsey.com/capabilities/tech-and-ai/our-insights/delivering-large-scale-it-projects-on-time-on-budget-and-on-value
- McKinsey & Company — https://www.mckinsey.com/~/media/McKinsey/dotcom/client_service/BTO/PDF/MOBT_27_Delivering_large-scale_IT_projects_on_time_budget_and_value.ashx
- Neocode — https://www.neocode.com/blog/research-summary-delivering-large-scale-it-projects-on-time-on-budget-and-on-value-by-michael-bloch-sven-blumberg-jurgen-laartz-mckinsey-company-2012/
- Faeth Coaching — https://faethcoaching.com/it-project-failure-rates-facts-and-reasons/
- Medium — https://medium.com/@anirudh-manthaa/embracing-the-cloud-strategies-and-challenges-of-a-new-cios-push-for-cloud-migration-13eec9cc5f5e
- McKinsey & Company — https://www.mckinsey.com/about-us/overview/alliances-and-acquisitions/google-cloud-and-mckinsey
- McKinsey & Company — https://www.mckinsey.com/capabilities/mckinsey-digital/our-insights/in-search-of-cloud-value-can-generative-ai-transform-cloud-roi
- LeanIX — https://www.leanix.net/en/wiki/tech-transformation/cloud-migration-challenges
- Flexera — https://info.flexera.com/CM-REPORT-State-of-the-Cloud?lead_source=Organic+Search
- DataCenterKnowledge — https://www.datacenterknowledge.com/cloud/top-cloud-migration-challenges-and-how-to-face-them
- initOS — https://www.initos.com/en/blog/what-to-avoid-in-erp-implementation-project/
- Kpcteam — https://kpcteam.com/kpposts/top-erp-statistics-trends
- Computer Weekly — https://www.computerweekly.com/news/252446965/Lidl-dumps-500m-SAP-project
- DEV Community — https://dev.to/indika_wimalasuriya/amazon-prime-videos-90-cost-reduction-throuh-moving-to-monolithic-k4a
- Medium — https://medium.com/@Monika_Sharma1/why-amazon-prime-video-moved-from-serverless-to-monolithic-and-saved-90-costs-660a0d69ac71
- ByteByteGo — https://bytebytego.com/guides/amazon-prime-video-monitoring-service/
- Medium — https://medium.com/@princevermasrcc/when-monoliths-triumph-case-studies-of-reversing-microservices-adoption-6f0bb3fd055e
- DevOps — https://devops.com/microservices-amazon-monolithic-richixbw/
- DEVCLASS — https://www.devclass.com/ci-cd/2023/05/05/reduce-costs-by-90-by-moving-from-microservices-to-monolith-amazon-internal-case-study-raises-eyebrows/1621790
- DEVCLASS — https://devclass.com/2023/05/05/reduce-costs-by-90-by-moving-from-microservices-to-monolith-amazon-internal-case-study-raises-eyebrows/
- Legacyleap — https://www.legacyleap.ai/blog/monolith-vs-microservices/
- InfoQ — https://www.infoq.com/news/2018/07/segment-microservices/
- SoftwareSeni — https://www.softwareseni.com/understanding-modern-software-architecture-from-microservices-consolidation-to-modular-monoliths/
- MDPI — https://www.mdpi.com/2079-9292/13/8/1452
- Medium — https://medium.com/data-science/the-hindsight-guide-to-replatforming-1dc11f7933d4
- Medium — https://richmironov.medium.com/the-risks-of-replatforming-dbdc1de3a69d
- Mironov — https://www.mironov.com/replatforming/
- Medium — https://medium.com/@marc.bara.iniesta/the-missing-data-why-we-dont-really-know-if-big-companies-fail-more-at-tech-projects-311349cadbb9
- TechRepublic — https://www.techrepublic.com/article/how-a-troubled-sap-s4hana-migration-caused-a-gummy-bear-shortage-in-germany/
- Sapbwconsulting — https://www.sapbwconsulting.com/blog/lidl-sap-failure
- Spinnaker Support — https://www.spinnakersupport.com/blog/2023/12/13/erp-implementation-failure/
- Computer Weekly — https://www.computerweekly.com/news/252464278/SAP-disruption-leads-to-Revlon-class-action-lawsuit
- Brightwork Research — https://www.brightworkresearch.com/what-was-the-real-story-with-the-revlon-s-4hana-failure/
- TechTarget — https://www.techtarget.com/searcherp/news/252464165/Revlon-SAP-ERP-problems-result-in-rare-investor-lawsuit
- Data Center Dynamics — https://www.datacenterdynamics.com/en/news/total-cost-of-birmingham-citys-oracle-system-failure-to-reach-2165m-by-2026-report/
- The Register — https://www.theregister.com/2024/08/20/birmingham_oracle_cost/
- Military Times — https://www.militarytimes.com/news/pentagon-congress/2026/04/10/after-three-year-hiatus-va-to-resume-rollout-of-new-electronic-medical-records-system/
- Nextgov.com — https://www.nextgov.com/modernization/2025/12/va-readies-restart-ehr-deployments-2026-despite-lingering-lawmaker-unease/410311/
- Federal News Network — https://federalnewsnetwork.com/it-modernization/2026/04/va-ehr-rollout-resumes-after-three-year-pause/
- Panorama-consulting — https://www.panorama-consulting.com/nhs-it-system-failure/
- LinkedIn — https://www.linkedin.com/pulse/top-10-reasons-why-emr-implementations-fail-udai-kumar
- IEEE Spectrum — https://spectrum.ieee.org/the-us-air-force-explains-its-billion-ecss-bonfire
- Defense Daily — https://www.defensedaily.com/air-forces-canceled-itprogram-ecsswas-simply-toobig-mcgrathsays/air-force/
- TechSpot — https://www.techspot.com/news/79848-hertz-hits-accenture-32-million-lawsuit-over-failed.html
- Decision Resources — https://www.decision.com/candy-free-halloweens-haribo-and-hersheys-failed-erp-projects/
- CIO — https://www.cio.com/article/278677/enterprise-resource-planning-10-famous-erp-disasters-dustups-and-disappointments.html
- Thirdstage-consulting — https://www.thirdstage-consulting.com/blog/lessons-from-the-us-air-force-oracle-erp-failure/
- Whatfix — https://whatfix.com/blog/ehr-implementation/
- KLAS Research — https://klasresearch.com/archcollaborative/report/ehr-implementations-2025/628
- Carepatron — https://www.ehrinpractice.com/ehr-failure-statistics.html
- KMS Healthcare — https://kms-healthcare.com/blog/healthcare-cloud-migration/
- Quote Park — https://quotepark.com/quotes/1872956-fred-brooks-the-second-system-effect-an-architects-first/
- Wikipedia — https://en.wikipedia.org/wiki/Second-system_effect
- Joel on Software — https://www.joelonsoftware.com/2000/11/20/netscape-goes-bonkers/
- Opensource.com — https://opensource.com/article/19/11/end-of-life-python-2
- Agileanalytics — https://www.agileanalytics.cloud/blog/team-topologies-the-reverse-conway-manoeuvre
- Wikipedia — https://en.wikipedia.org/wiki/Conway's_law
- CTO Craft — https://ctocraft.com/blog/how-can-the-inverse-conway-manoeuvre-help-drive-organisational-change/
- Grokipedia — https://grokipedia.com/page/Conway's_law
Commissioned from our research desk. Subject to final editorial discretion.